Roadmap to getting started
Step One: Introduction to the High Throughput Computing Strategy
Like nearly all large-scale compute systems, users of both CHTC’s High Throughput and High Performance systems prepare their computational work and submit them as tasks called jobs. These jobs run on execution points, which are the computers that perform the work.
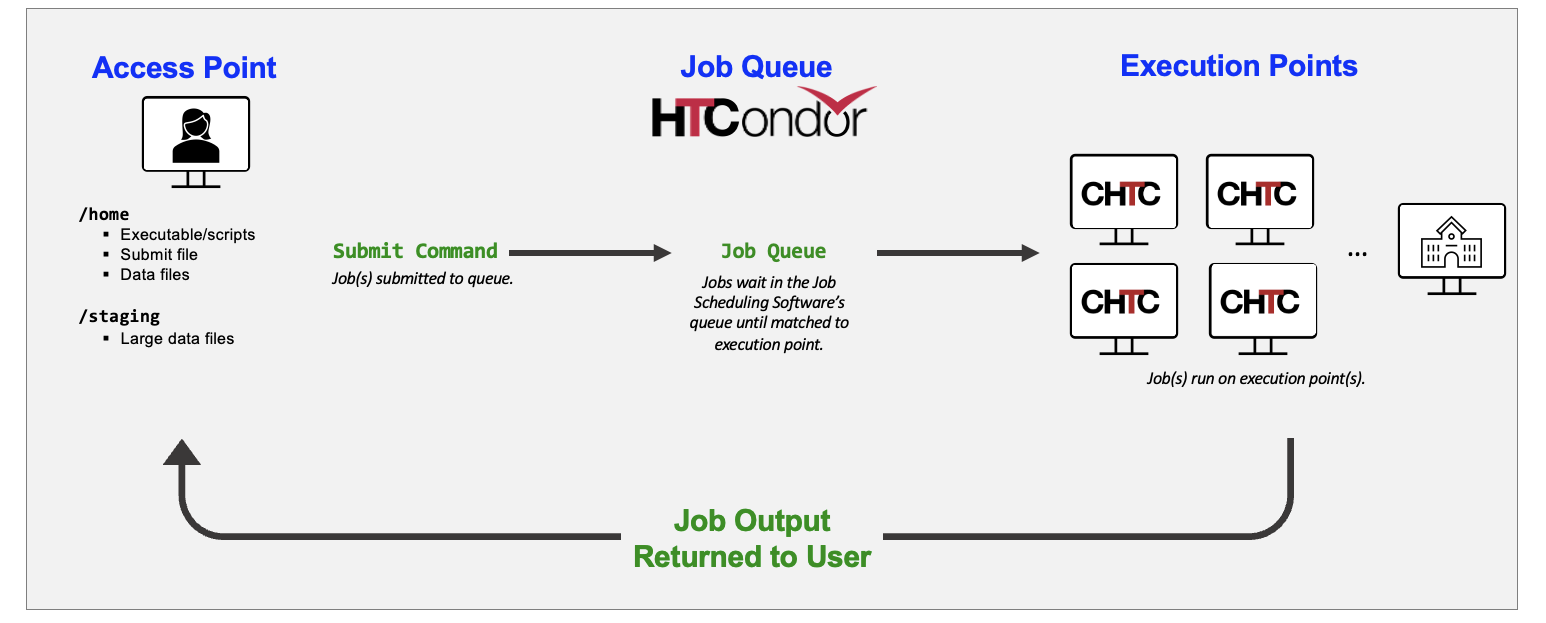
Terminology:
- The Access Point is where you log in and stage your data, executables/scripts, and software to use in jobs.
- HTCondor is a job scheduling software that will run your jobs out on the execution points.
- The Execution Points are the set of resources your job runs on.
High Throughput Computing systems specialize in running tens to millions small, independent jobs. On the other hand, High Performance Computing systems specialize in running a few, very large jobs that use multiple computers working together on the same problem.
| HTC (High Throughput Computing) | HPC (High Performance Computing) | |
|---|---|---|
| Best for... | Running several independent jobs | Running one very large job |
| Typical size | 1 - 4 CPUs/job | 30+ CPUs/job | Multiple computers work together on one task? | X | ✓ |
| Examples | Simulations, image processing, and machine learning workflows | Climate modeling, fluid dynamics, and large optimizations |
It is important to keep this distinction in mind when setting up your jobs. On the HTC system, smaller jobs that request fewer resources (CPU, memory, and disk) are generally easier to find a slot to run on, so they start more quickly, and you can have many of them running at the same time.
💡 Run smaller jobs when possible!
Rather than submitting one large job, consider splitting your workflow into multiple smaller, independent jobs whenever possible. This often leads to faster scheduling and more efficient use of HTC resources.
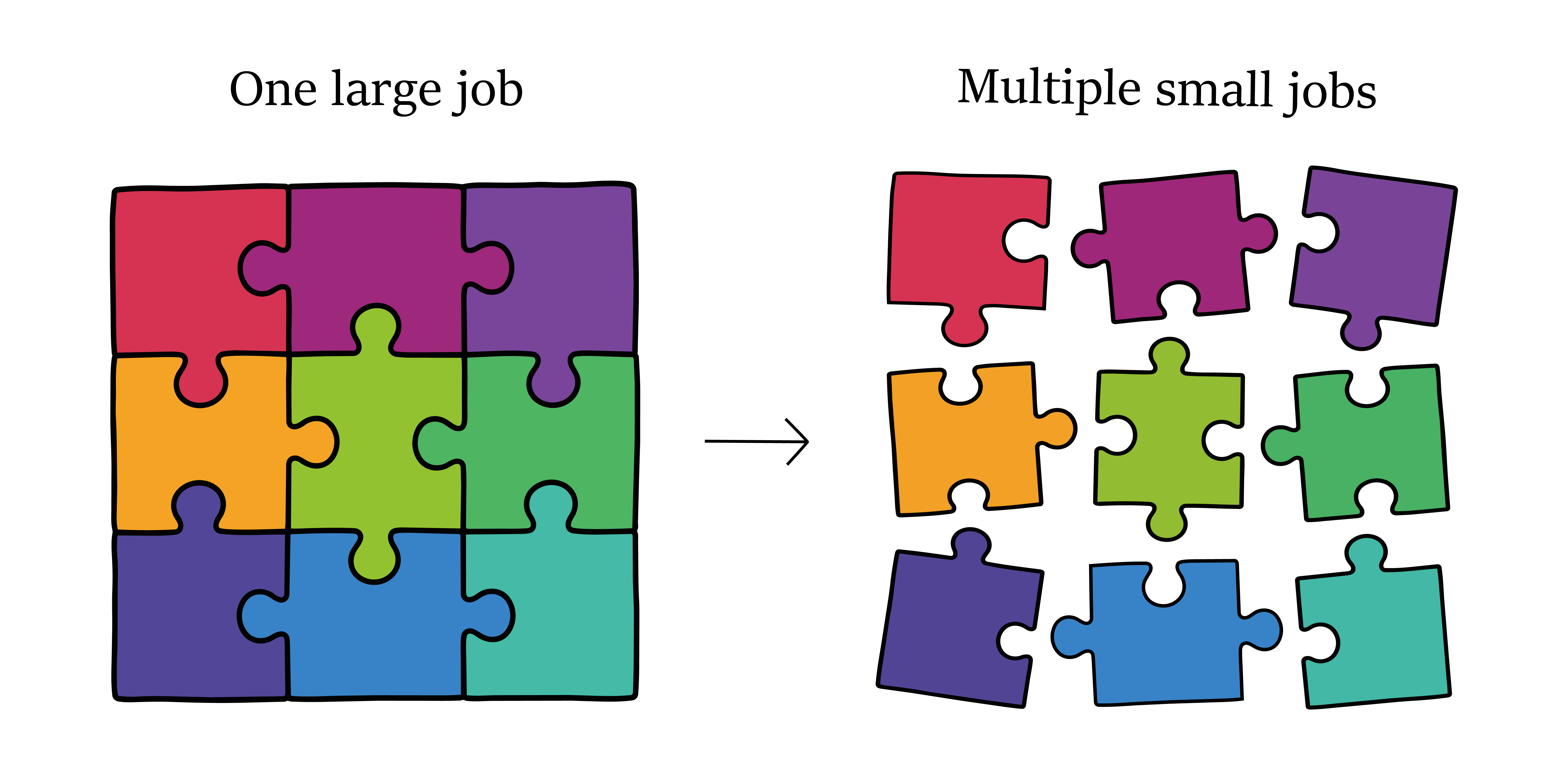
Unlike the High Performance System, CHTC staff do not limit the number of jobs a user can have running in parallel, thus it is to your advantage to strategize your workflow to take advantage of as many compute resources as possible.
More detailed information regarding CHTC’s HTC system can be found in the HTC Overview Guide.
Step Two
Log on to an HTCondor HTC Access Point
Before you can submit jobs, you need access to a CHTC account. If you have not requested an account yet, start by filling out the 📋 CHTC account request form.
Once you receive your login information by email, you are ready to begin!
To use CHTC, you first log in to an access point. An access point, also called a submit server, is the computer you connect to before your jobs run. It is where you prepare your files, write your submit instructions, and send your jobs to HTCondor.
For security purposes, every CHTC user is required to be connected to either a University of Wisconsin internet network or campus VPN and to use two-factor authentication when logging in.
See how to 💻 Log In to CHTC Resources.
Step Three
Understand the Basics of Submitting HTCondor Jobs
Computational work is run on the the High Throughput Computing system's execution machines by submitting tasks as “jobs” to the HTCondor job scheduler. Before submitting your own computational work, it is necessary to understand how HTCondor job submission works.
It is highly recommended that every user follow this short tutorial as these are the steps you will need to know to complete your own analyses.
Step Four
Learn to Run Many HTCondor Jobs using one Submit File
After following this tutorial, we highly recommend users review the Easily Submit Multiple Jobs guide to learn how you can configure HTCondor to automatically pass files or parameters to different jobs, return output to specific directories, and other easily automated organizational behaviors.
Step Five
Install your Software
Our Software Solutions guides contain information about how to install and use software on the HTC system.
Software Containers
In general, we recommend installing your software into a "container" if your software relies on a specific version of R/Python, can be installed with
conda, if your software has many dependencies, or if it already has a pre-existing container (which many common software packages do). There are many advantages to using a software container; one example is that software containers contain their own operating system. As a result, jobs with software containers have the most flexibility with where they run on CHTC or the OSPool. The CHTC website provides several guides on building, testing, and using software containers.
Use Pre-installed Software in Modules
CHTC's infrastructure team has provided a limited collection of software as modules, which users can load and then use in their jobs. This collection includes tools shared across domains, including COMSOL, ANSYS, ABAQUS, GUROBI, and others. To learn how to load these software into your jobs, our Use Software Available in Modules and Use Licensed Software guides.
Access Software Building Tools on CHTC's Software Building Machines
The HTC system contains several machines designed for users to use when building their software. These machines have access to common compilers (e.g., gcc) that are necessary to install many software packages. To learn how to submit an interactive job to log into these machines to build your software, see Compiling or Testing Code with an Interactive Job.
Step Six
Access your Data on the HTC System
Upload your data to CHTC
When getting started on the HTC system, it is typically necessary to upload your data files to our system so that they can be used in jobs. For users that do not want to upload data to our system, it is possible to configure your HTCondor jobs to pull/push files using
s3 file transfer, pull data using standard unix commands (wget), among other transfer mechanisms.
To learn how to upload data from different sources, including your laptop, see:
- Transfer Files between CHTC and your Computer
- Transferring Files Between CHTC and ResearchDrive
- Using Globus to Transfer Files to and from CHTC
- Remotely Access a Private GitHub Repository
Choose a Location to Stage your Data
When uploading data to the HTC system, users need to choose a location to store that data on our system. There are two primary locations:
/home and /staging.
/home is more efficient at handling "small" files, while /staging is more efficient at handling "large" files. For more information on what is considered "small" and "large" data files and to learn how to use files stored in these locations for jobs, visit our HTC Data guides.
Step Seven
Run Test Jobs
Once you have your data, software, code, and HTCondor submit file prepared, you should submit several test jobs. The table created by HTCondor in the
.log file will help you determine the amount of resources (CPUs/GPUs, memory, and disk) your job used, which is beneficial for understanding future job resource requests as well as troubleshooting. The standard out .out file will contain all text your code printed to the terminal screen while running, while the standard error .err file will contain any standard errors that your software printed out while running.
Things to look for:
- Jobs being placed on hold (hold messages can be viewed using
condor_q jobID -hold) - Jobs producing expected files
- Size and number of output files (to make sure output is being directed to the correct location and that your quota is sufficient for all of your output data as you submit more jobs)
Step Eight
Submit Your Workflow
Once your jobs succeed and you have confirmed your quota is sufficient to store the files your job creates, you are ready to submit your full workflow. For researchers interested in queuing many jobs or accessing GPUs, we encourage you to consider accessing additional CPUs/GPUs outside of CHTC. Information is provided in the following step.
Step Nine
Access Additional Compute Capacity
Researchers with jobs that run for less than ~10 hours, use less than ~20GB of data per job, and do not require CHTC modules, can take advantage of additional CPUs/GPUs to run there jobs. These researchers can typically expect to have more jobs running simultaneously.
To opt into using this additional capacity, your jobs will run on hardware that CHTC does not own. Instead, your jobs will "backfill" on resources owned by research groups, UW-Madison departments and organizations, and a national scale compute system: the OSG's Open Science Pool. This allows researchers to access capacity beyond what CHTC can provide. To learn how to take advantage of additional CPUs/GPUs, visit Scale Beyond Local HTC Capacity.
Step Ten
Move Your Data off CHTC
Data stored on CHTC systems is not backed up. While CHTC staff try to maintain a stable compute environment, it is possible for unexpected outages to occur that may impact your data on our system. We highly recommend all CHTC users maintain copies of important scripts and input files on another compute system (your laptop, lab server, ResearchDrive, etc.) throughout their analysis. Additionally, as you complete your analysis on CHTC servers, we highly recommend you move your data off our system to a backed up storage location.
CHTC staff periodically delete data of users that have not logged in or submitted jobs in several months to clear up space for new users. Eventually, all users should expect their data to be deleted off CHTC servers and should plan accordingly. Data on CHTC is meant to be used for analyses actively being carried out - CHTC is not a long-term storage solution for your data storage needs.